


Training
Data Center
更高效可靠的
训练集群效率

Inference
Data Center
更快速经济的
推理生成能力

Edge AI
Device & Data
Center
更高效灵活的
本地化部署方案

以芯粒和Mordernized RDMA构建AI集群全栈式互联
架构及产品解决方案





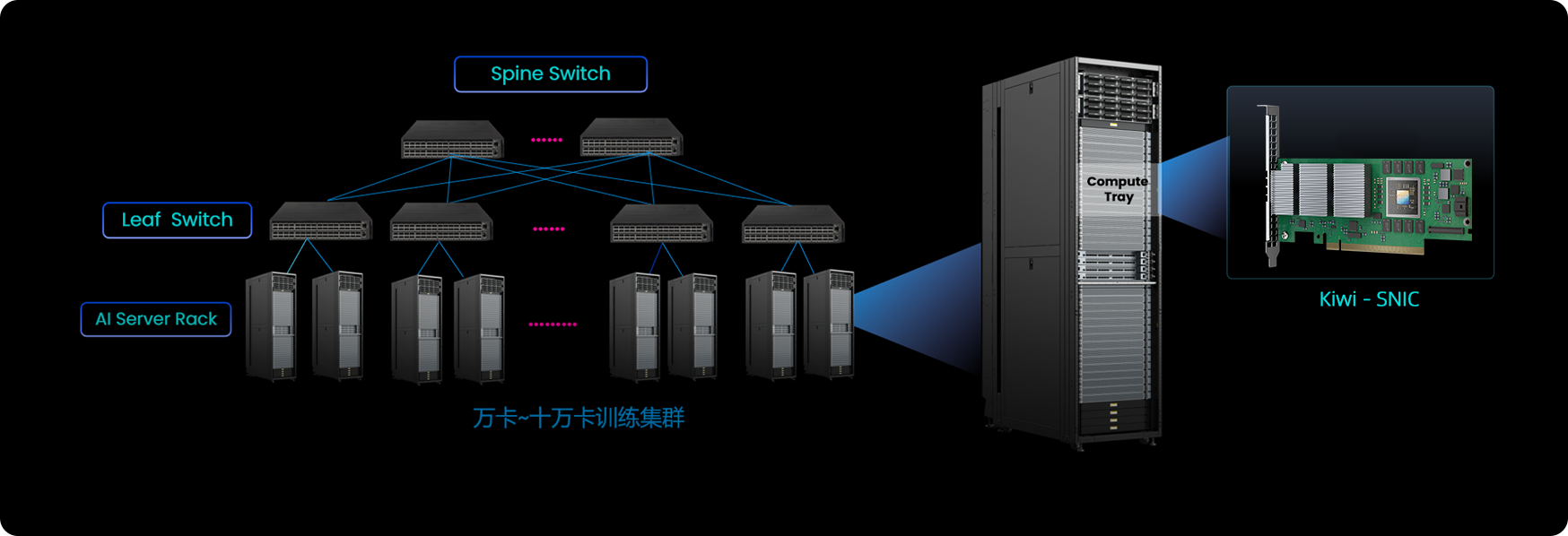
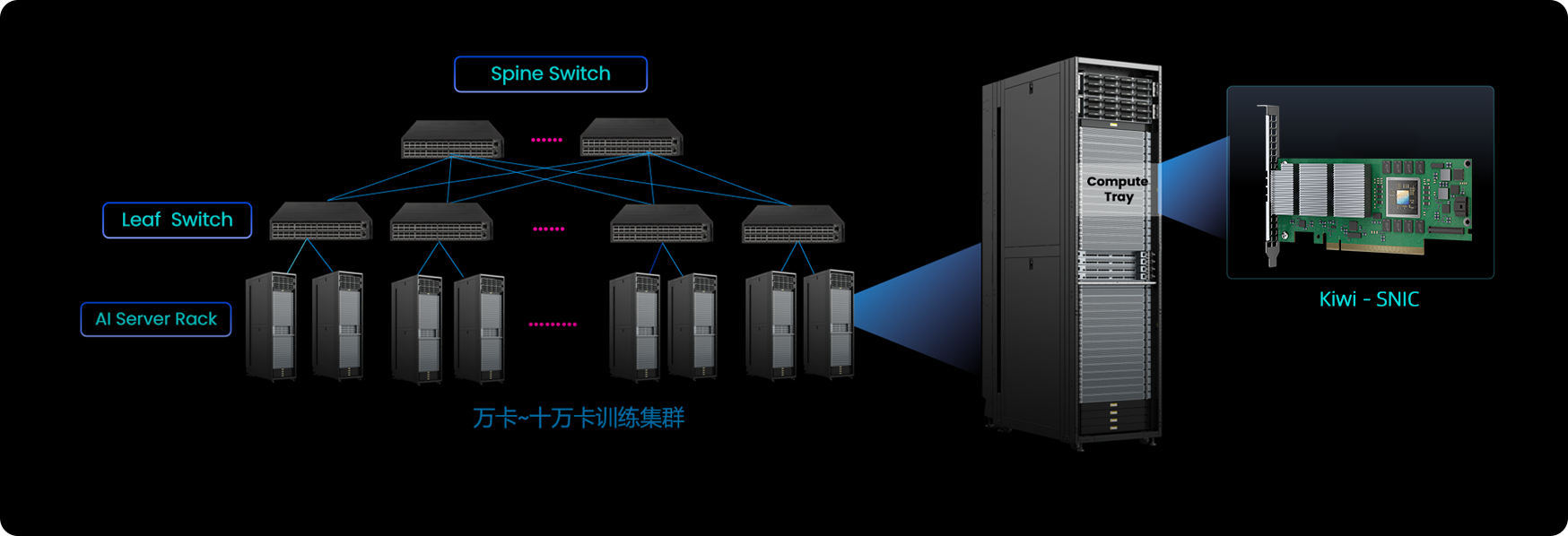
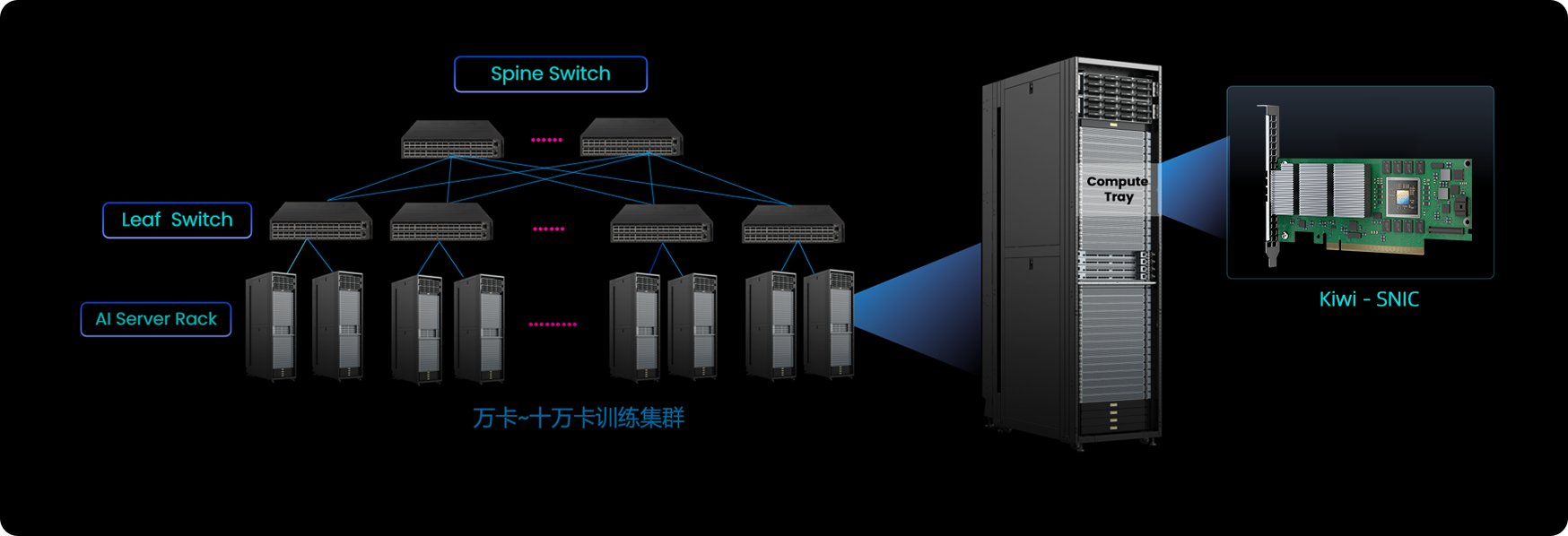
大模型参数量从千亿级向万亿级跃升,从预训练到后训练所需的算力呈指数级增长。例如,美国xAI的Grok 3模型训练消耗了20万张英伟达GPU。国内运营商/云厂商已经陆续建成万卡及以上级别智算中心并支持大规模分布式训练。
AI训练集群对于构建强大的基座模型至关重要。基座模型的训练依赖大量的计算资源。大模型训练所需的并行计算(如流水线并行、专家并行、张量并行)产生了海量的通信。因此要求大规模网络确保高吞吐能力、超高带宽、追求极低的延时、确保数据传输的无损性、实现快速故障恢复从而确保AI基础设施的利用效能。

训练集群
有效算力提升
超高带宽
极低延时

大规模
网络流控

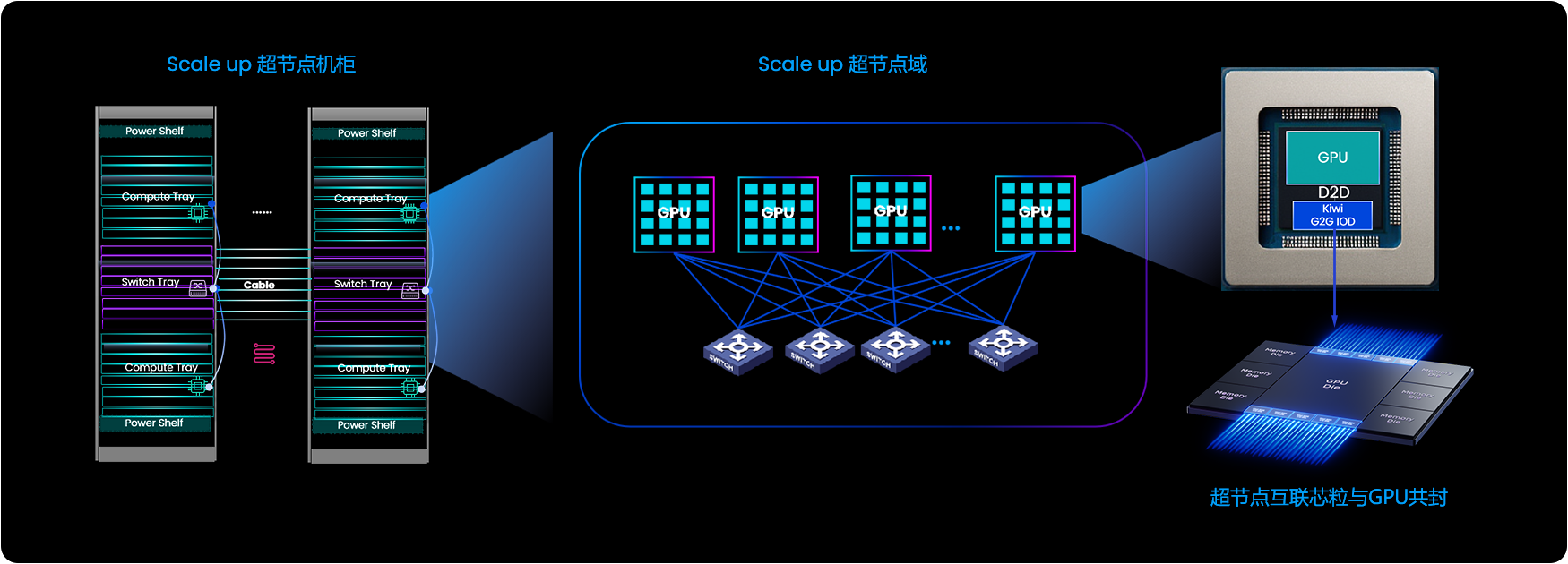
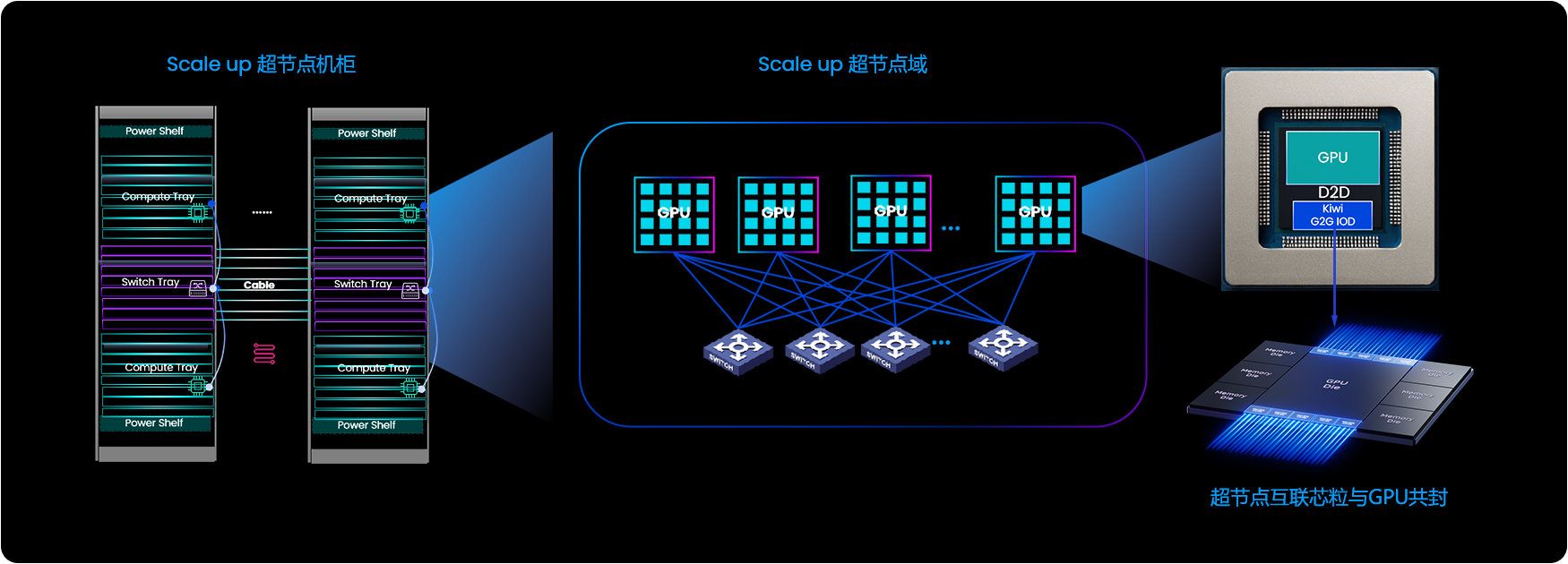
随着类似DeepSeek的推理模型加速AI在国内各行业的落地,支撑亿级用户并发、提升推理Token输出效率成为关键需求。这促使高效可靠的云端推理集群成为应对海量算力增长的核心。然而,模型并行对GPU间互联提出了严峻挑战,特别是高频、高量的张量并行与专家并行通信导致的时延、通信带宽不足等。
在此背景下,超节点技术应运而生,它将机架内成百上千GPU互联成一张“巨型GPU”,通过构建HBD系统,显著提升多种模型并行下的数据通信效率,已成为大模型推理的必然趋势。AI推理集群正呼唤开源开放的通用超级点片间互解决方案。

基于开放
开源的生态系统

更高性能且
经济的互联方案

适应推理基础
设施软硬件升级

边缘AI与本地化部署正成为主流趋势。Gartner预测,到2026年全球半数企业将在边缘部署AI能力。随着AI应用逐步渗透到全场景,模型正加速小型化,通过压缩体积、提升知识密度,更好地适配边缘计算场景。
这一趋势正驱动企业对本地AI及边缘集群部署的需求日益迫切,集群形态也随之演进,从个人桌面一体机、推理一体机设备,直至规模化企业集群,呈现多样化发展。在此背景下,互联仍然是本地及边缘AI基础设施的关键技术之一。

Tb级别传输性能

本地化部署灵活

提升边缘AI推理
部署效率

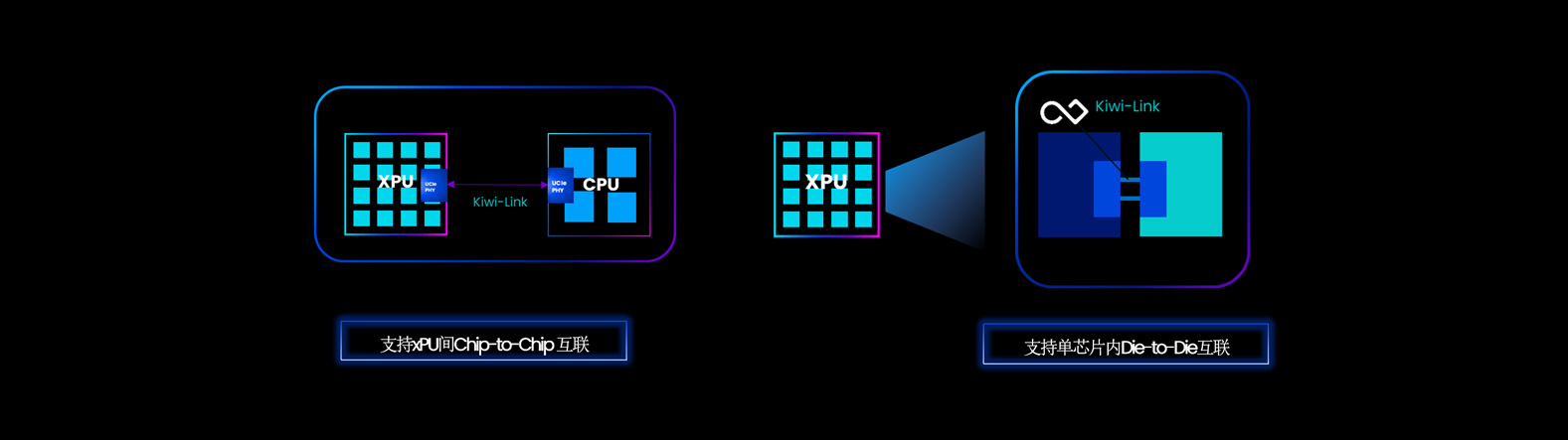
随着AIGC时代的到来,模型规模与数量的激增,尤其是大模型的逐步普及,使得算力需求呈指数级增长,对现有计算架构构成了严峻挑战。传统的同构计算模式在日益复杂的系统面前,已无法满足持续增长的算力渴求。芯粒技术正是应对这一挑战的破局之道。它通过将具备不同功能的模块芯片(芯粒)灵活集成于单一系统,不仅实现了高性能算力的聚合,更通过模块化解耦大幅提升了制造良率。
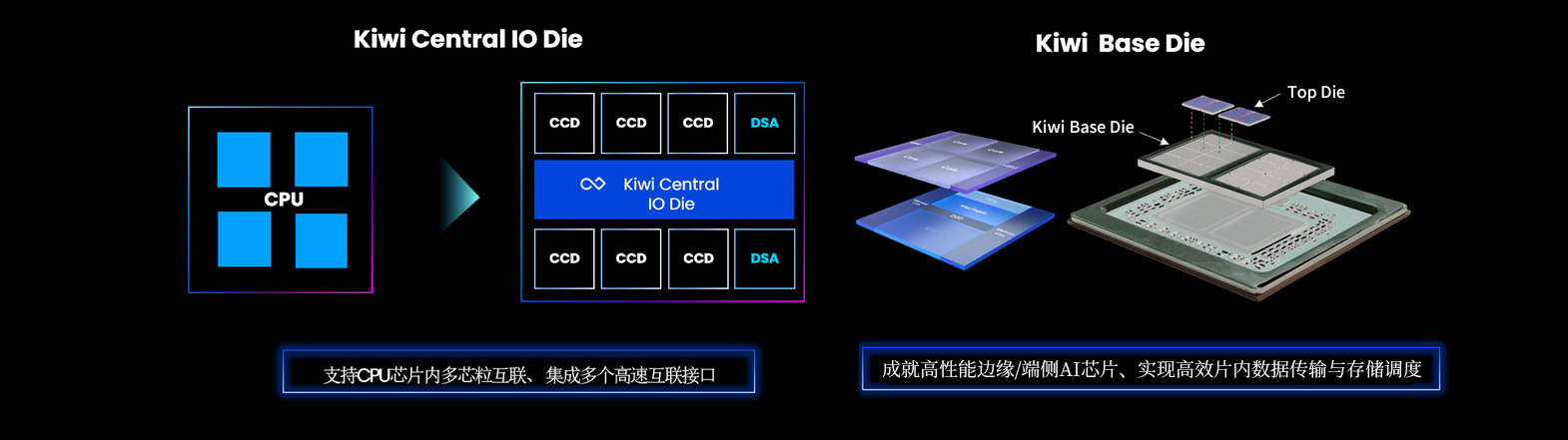
在单芯片层面,基于芯粒架构的IO芯粒与高效的Die-to-Die互联技术,是解锁芯片内部性能潜力的关键。而在更宏观的AI集群层面,CPU与各类xPU(如GPU、NPU等)之间的高速协同至关重要。基于通用协议的Die-to-Die IP 技术支持Chip-to-Chip互联,有效突破了传统PCIe接口的速率限制,成为实现集群内高效异构计算、加速AI系统运行的核心路径。

突破光罩
面积极限

提升芯片
制造良率
实现单芯片
算力扩展